2025年11月14日、米Disney社は、同社の映像配信サービス「Disney+」において、ユーザーの顔・声と既存のディズニーキャラクターを使用して、生成AIで静止画・動画を作成できる新機能「Disney+ Create」を実装すると発表。これは「子どもがディズニープリンセスやジェダイになれる」というような状況を想定している。
ディズニー社はこれまで一貫して生成AIに否定的な立場を取ってきた。2023年にUniversalと共同で画像生成AI「Midjourney」の開発元を著作権侵害で提訴し、2025年6月にはそこにWarner Bros.も加わった。結果として、ディズニーは反AIにとって「正義の味方」のようなポジションとなり、この世界に無断学習罪を誕生させる最大の希望として期待を集めていた。

https://x.com/ikariharahara/status/1933031408110612663

https://x.com/innocence_SAC/status/1932952343034855768
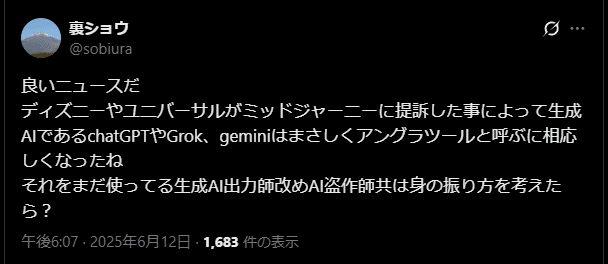
https://x.com/sobiura/status/1933088751296946208
しかし結局のところ、ディズニーは「自社IPが他社によって学習・出力される」という状況が許せなかっただけであり、生成AIに否定的ではないのはもちろん、「みんな被害者、みんなで助かろう」の無断学習罪にも全く興味が無かったわけである。Disney+ Createがどのような生成AIであるにせよ、基盤技術が一切何も無断学習せずに作られた物とは到底考えられない。反AIはそれを一生「問題だ」と言い続けるだろうが、ディズニーは「問題ない」と考えている。