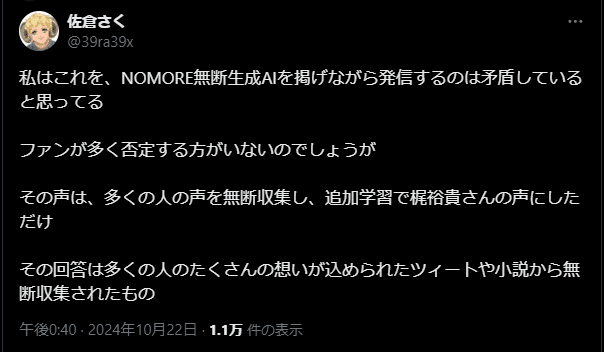
2024年10月15日、「声優有志の会」が、Twitter、Youtube、およびTikTokで「NOMORE無断生成AI」という名称のアカウントを開設。声優本人が話す動画を用いてロビー活動を開始した。
https://x.com/NOMORE__MUDAN/status/1846159093221736917
ニュースリリースに日本俳優連合の名前は出てこないが、「NOMORE無断生成AI」は2024年2月19日に日俳連が作成したTwitterタグの名称そのものなので、これは実質的に日俳連の活動とみられる。
 https://x.com/JAU_GD/status/1759515165098451266
https://x.com/JAU_GD/status/1759515165098451266
一見してよくある話に見えるが、実は日本俳優連合の主張は、既存の反AIの主張とは全く異なる。その違いは特に下記のテキストに強く現れている。
■私たちの定義する「無断生成AI」とは
実演家、著作権者の許諾なく、無断で追加学習、生成、公開されたAI生成物のこと。2024年10月現在の法律では「情報解析のための学習」「非享受目的の学習」は著作権法の範囲外とされていますが、追加学習は議論が分かれます。誰の声か、誰の表現かということがわかるAI生成物は、著作権だけでなく人格権にも抵触する可能性があります。
https://news.yahoo.co.jp/articles/5f0fc7bb63970a6c579bc457d3468216c0291ac9?page=2
特定の声優のデータを「追加学習、生成、公開」する事を指して「無断生成」だと言っており、その一方で「無断学習」という単語は一切出てこない。つまり、日俳連が興味を持っているのは「無断生成罪」であって、実在しない「無断学習罪」の方ではない。
日俳連のキャンペーンが、「プロの声優が名指しでデータを作られ勝手に売られている」という具体的な被害者と被害内容を示し、追加学習と最終生成物に争点を絞り、新法を作って規制して欲しいとは一言も言っていないのに対し、反AIは「少しでも学習された可能性がある者は等しく被害者として扱う」というアプローチでベースモデルの学習段階を争点とし、具体的な被害者や被害内容を挙げず、その状態で「法規制して無断学習罪を作りAIを撲滅せよ」と主張しているので、方向性が全く逆である。
主張の方向性が全く違うにも関わらず、反AIは日俳連が作ったTwitterタグ「#NOMORE無断生成AI」を使用しているため、事実上タグを乗っ取った状態になっている。日俳連から見ると極めて迷惑な行為だと思うが、そもそも「反AIの主張と日俳連の主張が異なっている」という事に気付いていない反AIも多く、わりと地獄である。